Overview
Gulp.ai is a San Francisco-based, Y Combinator-backed AI company that enables AI self-improvement through real-time reinforcement learning. Their product unlocks AI-agent productivity at production scale by giving systems the missing piece for being continuously useful: the ability to learn from their own interactions in the field.
The team needed to integrate SGLang as a backend for model inference during LLM fine-tuning via VeRL, a reinforcement-learning framework purpose-built for fine-tuning large language models. The goal was to lift GPU utilization across the training loop so their fixed compute budget would deliver more iterations per dollar — without the platform team becoming Kubernetes operators.
ForthClover scoped the work as a fully managed AWS architecture built on Amazon SageMaker HyperPod, with a custom Docker image that satisfied the team's CUDA, PyTorch, and Python compatibility requirements and slotted into HyperPod's EKS orchestration without bespoke glue code.
AWS architecture
The architecture is organised into four layers that together give the Gulp.ai team a reproducible, fault-tolerant training environment without exposing the underlying cluster mechanics.
Architecture diagram
Gulp.ai AWS architecture
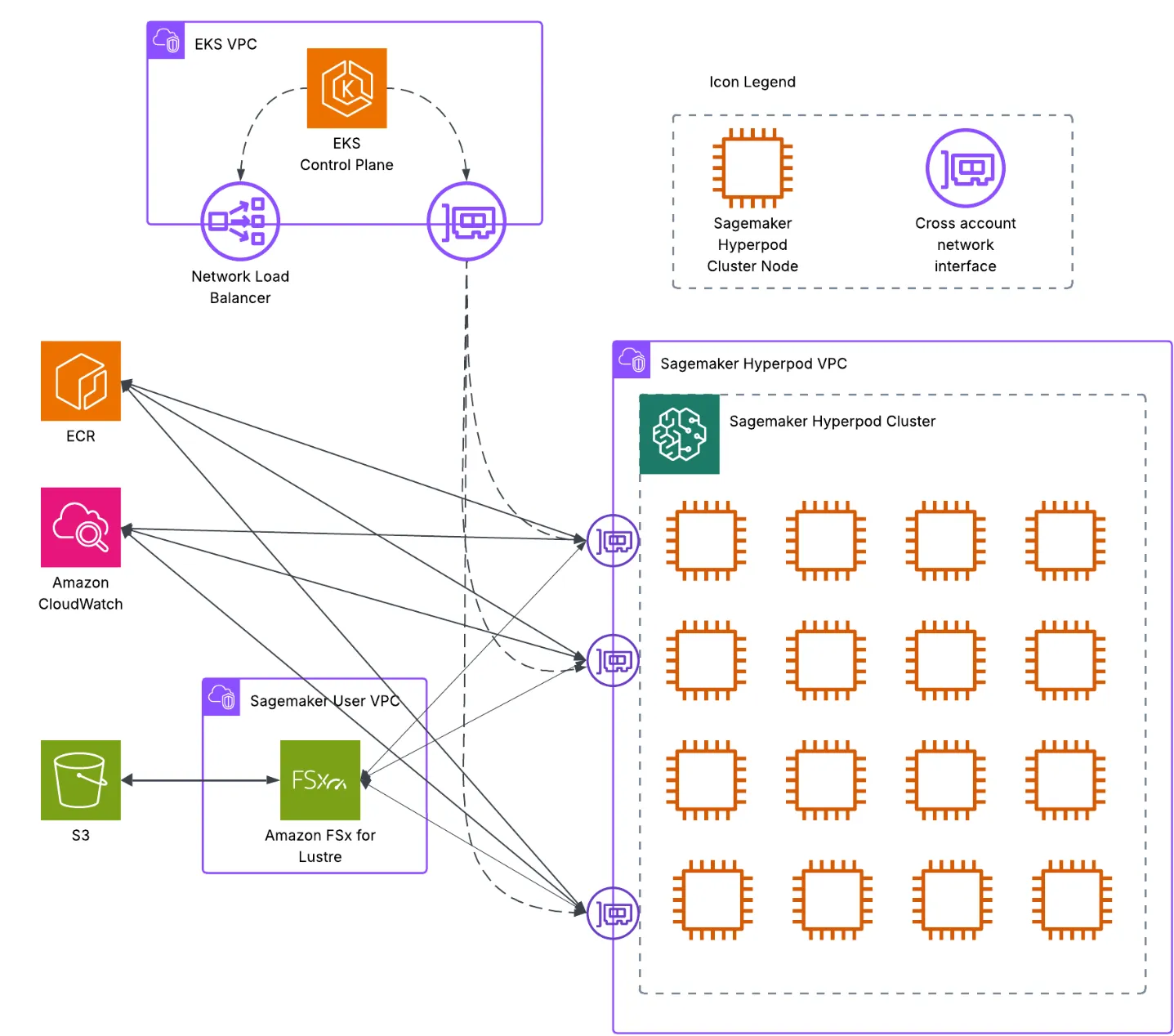
Complete AWS architecture for Gulp.ai's LLM fine-tuning pipeline with SageMaker HyperPod, VeRL, and SGLang.
Network layer
- Amazon VPC: isolated networking environment with public and private subnets across multiple availability zones for redundancy.
- Security groups: tight ingress rules between EKS, HyperPod cluster nodes, and the VeRL training jobs that speak to them.
- EFA support: Elastic Fabric Adapter networking for high-throughput, low-latency communication between GPU nodes during distributed training.
- VPC endpoints: private routes to S3, ECR, and CloudWatch so the cluster never has to traverse the internet for AWS service calls.
Compute layer
- Amazon SageMaker HyperPod: the central orchestration service that owns the training-cluster lifecycle — provisioning, scaling, recovery, and resource optimization.
- Amazon EKS: Kubernetes orchestration managed by HyperPod, running the VeRL training workloads as containerised jobs.
- Ray cluster: distributed-computing layer inside the Hyperpod environment, handling fan-out for both training and inference steps in the RL loop.
- GPU instance types: high-performance GPU instances optimised for ML workloads, sized and replaced by HyperPod as load shifts.
Storage layer
- Amazon S3: durable storage for training data, model artifacts, checkpoints, and Docker images.
- Amazon FSx for Lustre: high-performance shared file system surfaced to every training node so dataset reads do not become the bottleneck.
- Amazon EBS: persistent block storage backing the container instances themselves.
- Amazon ECR: private registry for the custom VeRL/SGLang Docker images, version-pinned to each training run for reproducibility.
Orchestration layer
- SageMaker HyperPod: primary orchestrator managing cluster lifecycle, job scheduling, and resource allocation.
- KubeRay operator: manages Ray-cluster lifecycle inside Kubernetes, owned by HyperPod.
- Helm charts: NVIDIA device plugins, EFA drivers, and supporting workloads installed declaratively so the cluster bootstrap is reproducible.
- Kubernetes Jobs: the actual training jobs execute as standard K8s Job resources, making them visible to existing tooling.
Benefits
The VeRL Docker integration with SageMaker HyperPod delivered measurable gains across performance, operations, cost, and developer experience.
Performance Optimization
- Enhanced GPU utilization: SGLang's efficient inference path during training removed the slack we were seeing on the original pipeline.
- Reduced training time: the integration of SGLang for inference phases cut overall training time through better memory usage and faster token generation.
- Scalable architecture: the SageMaker HyperPod and Ray-cluster combination moves smoothly from single-node to multi-node training without code changes.
- SageMaker training plans: the team can reserve and maximise GPU capacity for large-scale runs without scrambling for instances at launch time.
Operational Excellence
- Managed infrastructure: HyperPod removes the operational burden of running the underlying training cluster by hand.
- Containerized deployment: Docker-based packaging keeps environments identical from local development through staging and into production.
- Infrastructure-as-code: the entire stack is described in Terraform, version-controlled and reproducible across environments.
- Fault tolerance: automatic recovery from instance failures and workload migration across availability zones for long-running training jobs.
Cost Efficiency
- Managed-services integration: using HyperPod's managed control plane reduces the operational overhead and on-call cost of running training infrastructure.
- Flexible deployment options: support for both EKS node groups and HyperPod-managed clusters lets the team pick the right cost profile per workload.
- Pay-per-use model: HyperPod removes the need for permanently-on cluster capacity between runs.
- Cost management: SageMaker training plans give visibility into reserved spend so the team can plan large training cycles in advance.
Developer Experience
- Simplified deployment: Helm-based deployment streamlines what would otherwise be a multi-day cluster bring-up into a single command.
- Comprehensive monitoring: CloudWatch and the Ray dashboard give the team end-to-end visibility into training progress and resource utilization.
- Flexible configuration: environment-specific configuration enables proper CI/CD practices around training.
- Reduced complexity: HyperPod abstracts the infrastructure plumbing so the Gulp.ai team can stay focused on model and pipeline work.
The VeRL integration with SageMaker HyperPod transformed Gulp.ai's LLM fine-tuning capabilities, delivering measurable improvements in GPU utilization and training efficiency. By integrating SGLang for inference inside the reinforcement-learning loop, the solution shortened training time without compromising model quality. ForthClover was proud to partner with Gulp.ai to architect this scalable, cost-aware infrastructure that lets them continuously improve their AI agents through real-world feedback loops at production scale.